
How to Execute White-Space Patent Research with PatSnap as Exemplified using the CRISPR Gene Editing Technology
James H. Moeller - Moeller Ventures, LLC - https://www.moellerventures.com/
October 10, 2022
This report presents a tutorial on executing patent document white-space research using the PatSnap Connected Innovation Intelligence platform. This is a follow-on to the patent landscaping tutorial report (A Patent Landscaping Tutorial Using the PatSnap Analysis Tool and CRISPR as the Focus Technology) and will also use CRISPR as the focus technology. This report was also motivated by the 2021 National Institute of Health (NIH) project as part of providing commercialization assessments to SBIR (Small Business Innovation Research), and STTR (Small Business Technology Transfer) funded companies. The NIH project was executed for a contract awarded to Vikriti Management Consulting, where Moeller Ventures served as a subcontractor executing 200 patent landscapes for 164 life science companies.
Developing intellectual property is difficult. It usually involves significant R&D followed by the pursuit of patents via an expensive prosecution process that’s fraught with approval uncertainties. Leveraging white-space research into IP development has historically been expensive, problematic, and error-prone. It is, after all, the process of searching an IP sector for topic areas that are either lightly patented or void of any patent filings. This roughly equates to the paradoxical challenge of searching for IP that’s not present.
However, new analytics tools are dramatically changing the white-space research process by leveraging semantic analysis, natural language processing (NLP), and similarity assessment to identify landscape IP clusters as well as white-space IP voids. These processes can add significant value in analyzing a patent document domain collection, visualizing it on a landscape diagram, and querying the domain space for patenting opportunities. Furthermore, these automated techniques can be applied iteratively to gain significant insights into IP development.
Across the 164 companies and 200 patent landscapes provided in the NIH project, only a few companies seemed to understand the value of executing white-space research and its potential to augment the company's IP development process. This was surprising given the significant extent to which nearly every company relies on IP and patents to protect its inventions and market differentiating advantages. Ultimately white-space research can be used to focus R&D initiatives and draft better patent applications that avoid crowded landscape areas and improve the chances of having the patent approved.
The five steps of the white-space research process covered in this report are listed below.
Step 1: Determine the Context of the White-Space Research
Step 2: Create the Domain Collection of Patent Documents
Step 3: Generate the Landscape Diagram
Step 4: Query the Landscape Diagram
Step 5: Iterate the White-space Research Process
Inquiries regarding custom patent and intellectual property analysis using the PatSnap Connected Innovation Intelligence platform can be directed to the following individuals.
- Jim Moeller, Moeller Ventures LLC,
This email address is being protected from spambots. You need JavaScript enabled to view it. , 651-454-4123 - Jolly Nanda, VIKRITI Management Consulting, Contact: https://vikriti.com/contact-us-2/
- Michele Zoromski, ZORO Consulting,
This email address is being protected from spambots. You need JavaScript enabled to view it. , 612-804-4291
Step 1: Determine the Context of the White-Space Research, i.e., “CRISPR Nuclease”
Determining the context of the white-space research is essential in establishing the patent document query that will be used to create the domain collection for the analysis. This step typically requires a relatively high level of detailed insight into the topic area on which the white-space research will be focused and is often directly linked to development initiatives that initially motivate the inquiry. For example, a business may have a product development project where it believes it is establishing patentable IP, and it uses a specific set of keywords and phrases to create a white-space analysis domain collection. Alternatively, maybe it’s a university research initiative that has been granted a patent in a specific area, and it uses a semantically similar patent document query to create a domain collection that can be searched for other nearby patenting opportunities.
For this CRISPR white-space research example, it is helpful to start with some cursory background on the CRISPR gene editing technology that can provide insight into an approach for an instructive white-space analysis. CRISPR is broadly known as the biological technology that enables the editing of DNA (deoxyribonucleic acid), which makes up the genetic material of all living things. Since the invention of the CRISPR gene editing technology in 2012, patenting activities in this area have increased dramatically across a wide variety of complex topics, with each topic potentially an area that can be explored for white-space patenting opportunities. However, those topics all likely require significant expertise to determine the context of the analysis and are thus not good instructive examples. But a more fundamental examination of CRISPR reveals a more straightforward white-space research example: an analysis focused on the CRISPR nuclease.
CRISPR is named for the repeating pattern of nucleotides found in a specialized region of the DNA backbone. The acronym is derived from the phrase “Clusters of Regularly Interspaced Short Palindromic Repeats.” Nucleotides are organic molecules that are essentially the building blocks of DNA and RNA. However, the CRISPR gene editing technology is often described as having two components, a guide RNA and a nuclease protein. The guide RNA is similar to a shorter segment of DNA, but it can be programmed to search for and recognize specific sequences or genes within a DNA strand. This is combined with a nuclease protein responsible for executing some action on the DNA strand. For example, one of the initial and more popular nucleases associated with CRISPR is Cas9, which performs the action of cutting out the targeted gene. Various additional types of nucleases have also been associated with CRISPR, including Cas3, Cas12, Cas13, CRISPR-Csm, and others. Each nuclease can act on DNA (and RNA) in different ways. CRISPR nuclease research is one of the more active areas producing additional fundamental patents for editing genetic material. As a result, an instructive CRISPR white-space analysis can focus on these nuclease developments and simply utilize the various nuclease names to exemplify the white-space research.
Step 2: Create the Domain Collection of Patent Documents
Armed with the context of the white-space research, the next step is to create the domain collection of patent documents that will be used in the analysis. For white-space research, in particular, it is desirable to make the domain collection as broad as possible, given the context constraints. After all, white-space research is focused on finding new patenting opportunities. Any relevant references can potentially be prior art barring new patents, regardless of whether those references are in any section of pending applications, active granted patents, abandoned applications or patents, or expired patents.
Various techniques can create a domain collection specifically for white-space research. For example, keywords and key phrases can be used as queries into worldwide patent databases to find relevant documents representing topics or technology sectors. This type of text query can match specific text in a patent document title, abstract, description, or claims, with keywords and phrases matched across all sections. In addition, domain collections can be created by applying machine learning (ML) and natural language processing (NPL) techniques to identify semantically similar patent documents to a seed document or a set of seed documents. Most patent analytics services offer some type of NPL-enabled semantic search capability that enables users to create domain collections via this technique.
This CRISPR white-space research example will focus on the nuclease protein of the gene editing capability. As a result, the patent document query will be kept simple and utilize a keyword query using the keywords “CRISPR” and “nuclease.” Within PatSnap, the search can be executed either by the Simple search or the Field search options, but either way, it is essential to perform the search over all sections of the patent documents (title, abstract, description, and claims). The Simple search defaults the keyword query to all sections, whereas the Field search requires selecting “Title/Abstract/Claims/Description” from the text search options. Entering the keywords “CRISPR” and “nuclease,” not enclosed by quotes, returns 49,905 patent documents representing 14,002 simple patent families. This query looks too broad as it returns many documents where the keywords are used independently. Entering the phrase “CRISPR nuclease,” enclosed in quotes, returns a much more manageable domain collection of 3,374 patent documents representing 838 simple patent families and more likely focuses the patent documents specifically on those nucleases directly associated with CRISPR. Once the search results are generated, the patent documents can be saved to a workspace within PatSnap. Finally, it’s also worth noting that the domain collection results may not include the most recent patent filings due to publication delays for applications, such as the 18-month publication delay for USPTO-filed applications.
Step 3: Generate the Landscape Diagram
Before generating the landscape diagram, it’s essential to ensure that the patent documents are grouped with only one representative document per simple patent family. This grouping will eliminate duplicates of the same patent document filed in various worldwide jurisdictions and make the white-space research more straightforward to understand via the queries of step 4. Within PatSnap, the grouping setting is accessed under “Data Management” in the top-middle menu when viewing the tabular representation of the domain collection. Select “One representative per simple family” in the provided drop-down.
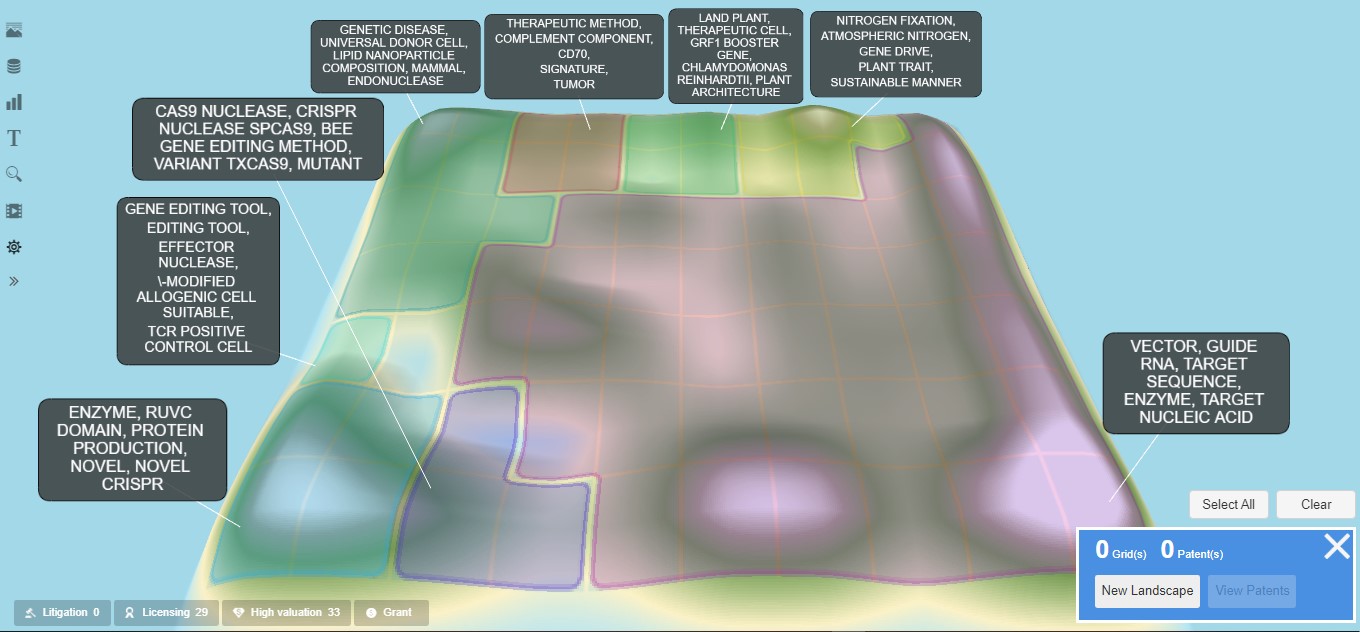
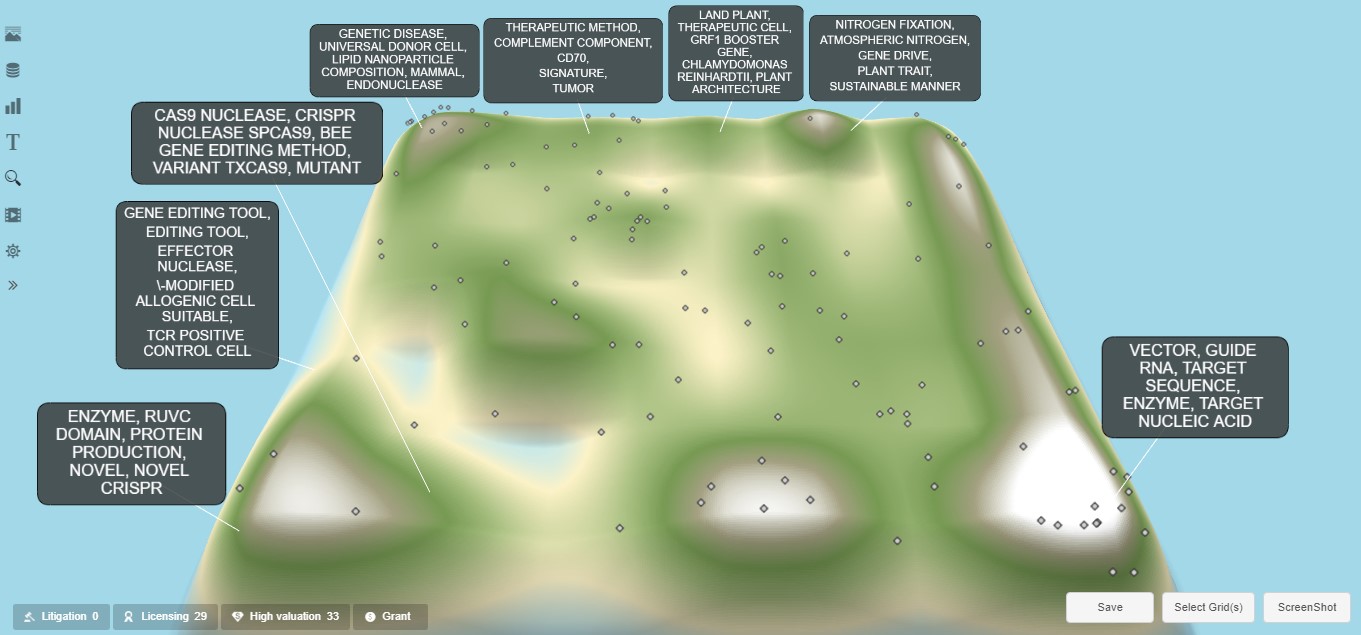
To generate the landscape diagram, select the “Analysis & Alerts” menu item from the top-middle menu of the tabular domain collection view and then select the “Landscape” option. This will open a new tab within your browser and display the default view of the landscape topography diagram (see Exhibit 1). This landscape topography is created by semantically grouping the domain collection patent documents. These groupings are shown on the topography according to the concentrations of semantically similar documents, with the high-level groupings positioned on the topography in a relatively semantically similar arrangement. The topography's peaks and valleys represent the document concentrations in the domain collection. For example, the white areas, like mountain peaks, represent the topic areas with the highest document concentrations. Successively lower document concentrations are represented by gray, dark green, lighter green, and light yellow. A light blue area represents an area completely lacking any documents. The high-level groupings can be shown via the “Select Grid(s)” option in the lower right corner, which shows the landscape grid and indicates each high-level semantic grouping via different shaded colors (see Exhibit 2).
The default landscape diagram also shows one keyword/key phrase callout textbox for each high-level grouping of the patent documents. These keywords or phrases are derived from the NPL analysis of the text of the patent documents in the high-level grouping and are designed to indicate the general grouping topic content. It’s often visually convenient to format and arrange these textbox callouts in preparation for the white-space analysis. Black backgrounds can be added to the text boxes via the “Setting” menu item to the left. The position of the textbox callouts can be adjusted via the “ScreenShot” option in the lower right corner. For the CRISPR nuclease analysis, the resulting landscape diagram is shown in Exhibit 1.
Finally, additional textbox callouts can be added on a per-grid basis via the left sidebar “Setting” option and the “Edit Label” capability. Adding additional callouts on a per-grid basis can sometimes help identify the high-level keywords or phrases in areas of interest, such as high-concentration areas or potential white-space areas. However, these additional high-level textbox callouts often lack the detail to provide real insight into potential patenting opportunities, as the keywords and phrases for each grid box are primarily derived from the higher-level grouping with only slight differences between grid blocks within a grouping.
Exhibit 1: “CRISPR Nuclease” Default Landscape Diagram
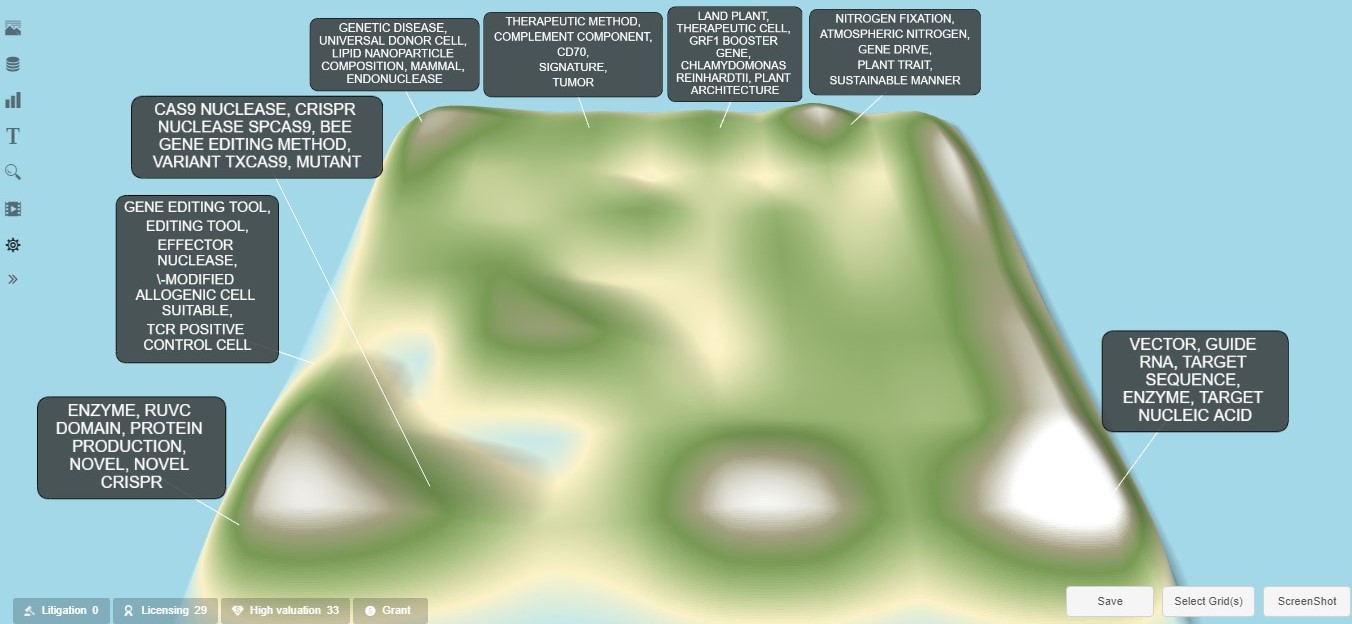
Exhibit 2: “CRISPR Nuclease” Default Landscape Diagram with Shaded Groupings
Step 4: Query the Landscape Diagram
The topographical landscape diagram can now be queried with keywords and key phrases to visually indicate the location and quantity of matching patent documents. Iterative keyword / key phrase queries can refine the search to reveal the topics that are either infrequently addressed, contained within more unique patent documents, or not addressed at all. This is essentially a visually interactive process of querying what’s present in the domain collection to gain insights into what’s not present or only lightly represented. The intelligent selection of domain-specific keywords and key phrases defines this search process, which is why this type of white-space research typically requires significant expertise in the research domain area.
Within PatSnap, the principal mechanism used to query the landscape diagram is the Search function in the left sidebar menu. This function has two modes of keyword / key phrase entry, a “Simple” search input and a “Field” search input. The Simple search uses any entered keywords or key phrases to query across all sections of every patent document in the domain collection. Any document matching the query will be shown on the landscape diagram as a gray dot. Specific key phrases are created by enclosing the relevant keywords in quotes. PatSnap’s Boolean search capabilities can also be used in the search input field. The Field search option works similarly, except that it allows the query to be further filtered by searching only in certain document sections (title, abstract, description, or claims) or by specifying other metadata about the patent documents (i.e., dates, assignees, inventors, etc.). While the Field search option is quite powerful, this white-space research example will only need to utilize the broader Simple search mechanism. After all, white-space research focuses on finding new patenting opportunities, which requires searching all sections of the patent documents in the domain collection that may contain prior art that limits or prohibits new patents.
As a simple initial example, Exhibit 3 shows the results when “cas9” is entered into the Simple search field. The landscape diagram becomes covered with gray dots. As a result of selecting the grouping option of “one representative per simple family,” each dot represents a unique patent document that includes “cas9” in either the title, abstract, description, or claims text. The high number of gray dots indicates that the Cas9 nuclease is a relatively thoroughly patented topic within this domain collection. This isn’t surprising since it is one of the initial and most widely developed nucleases associated with CRISPR. But as a result, finding white-space patenting opportunities with the Cas9 nuclease would likely require significant detailed research.
Exhibit 3: Landscape Query for “cas9”
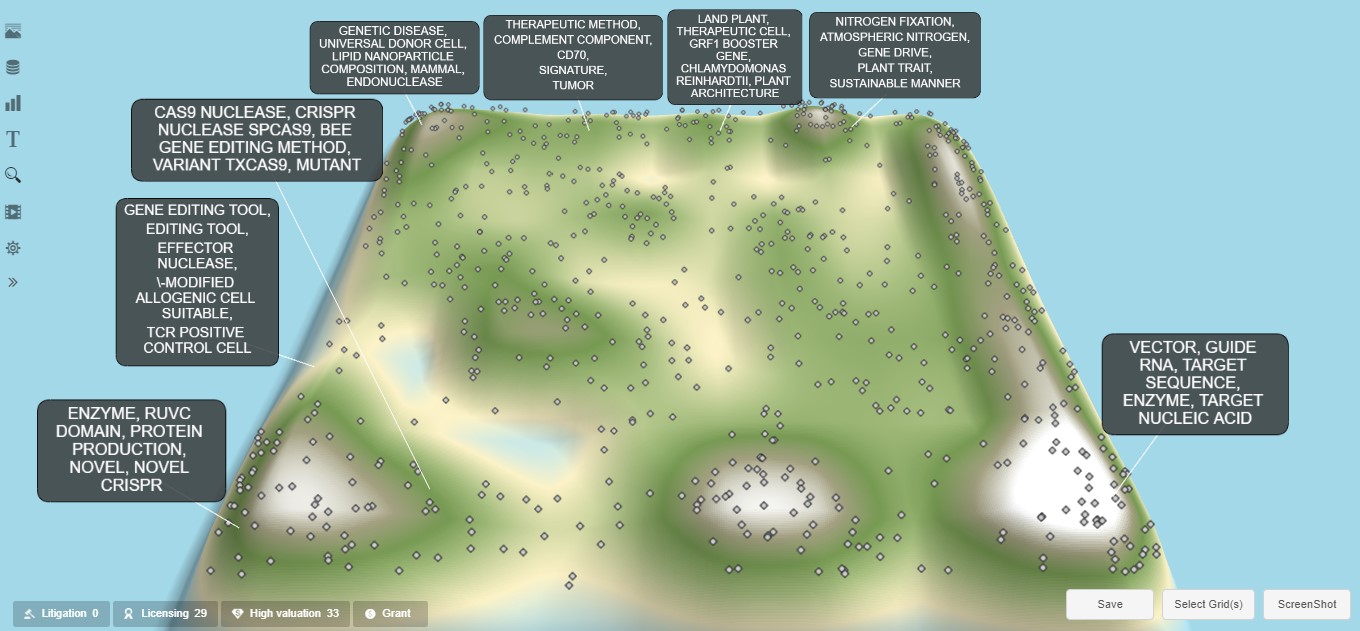
The location of the dots on the landscape diagram can also provide insightful information. In particular, dots that have landscape locations on or near high concentrations areas of the landscape (areas represented by the peaks on the topography) are potentially less unique. These patent documents have a higher risk of encountering more comparable and competitive IP and increased freedom-to-operate (FTO) issues. Conversely, patent documents located in low document concentration areas (the valleys on the topography) are potentially more unique with lower competitive risks and FTO limitations. As a result, query tactics focusing on the lower concentration areas of the landscape topography have a higher likelihood of uncovering white-space patenting opportunities.
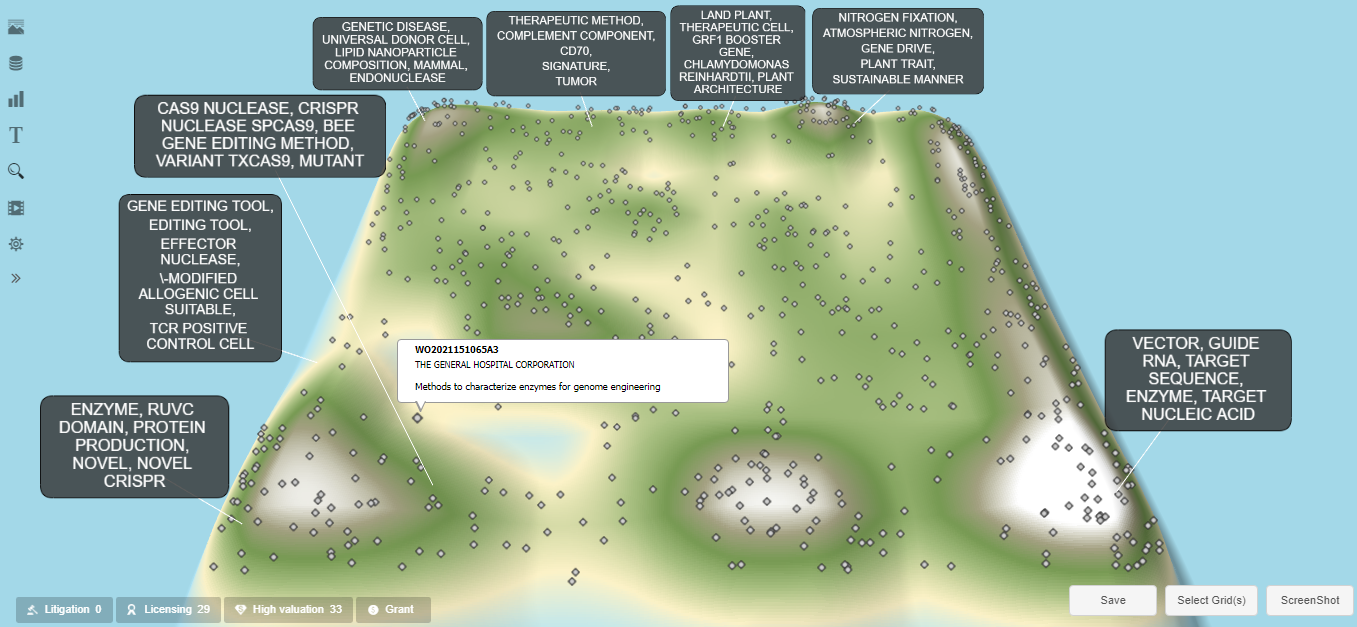
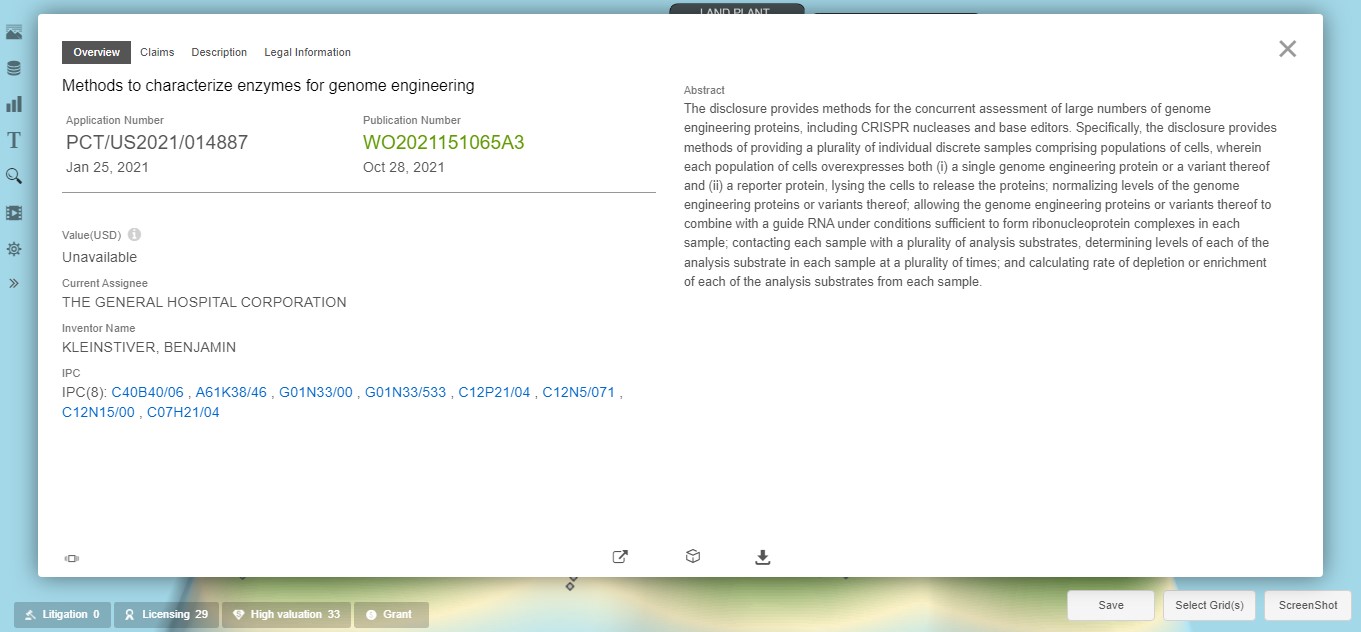
It is also instructive to note that the gray dots matching the search query are rendered on the diagram as mouse-over and interactive hyperlinks. Moving the cursor over a gray dot will automatically show a pop-up display of the patent document publication number and the document title and assignee. This is exemplified in Exhibit 4 for an international patent application (WO2021151065A3) filed by The General Hospital Corporation, more commonly known as Massachusetts General Hospital. This looks to be a relatively unique patent document with a placement in a topographical valley, which might merit more detailed research to determine why it is identified as being so unique. These pop-ups are very convenient for quickly scanning the documents in areas of interest on the landscape.
Exhibit 4: “cas9” Landscape with General Hospital Corporation Patent Document Highlighted
In addition, clicking on a gray dot will open a pop-up window that shows the full patent document in a tabbed format and provides links to download the patent document or open it in a separate window. This is exemplified in Exhibit 5 for the Massachusetts General Hospital patent application noted above. These pop-up windows are additional conveniences enabling more detailed review of patent documents on the landscape to quickly find and review the context of the matching keywords or key phrases and review the specific patent claims to develop an understanding of what’s represented in the invention. Understanding what’s already represented in the landscape diagram is a critical step in identifying what’s not represented and what could potentially be white-space patenting opportunities.
Exhibit 5: “cas9” Landscape with General Hospital Corporation Patent Document Clicked
As an additional example, “cas13” is entered in the Simple search field. Cas13 is a more recently discovered nuclease protein that seems to target RNA instead of DNA and can be used for identifying viruses. Exhibit 6 shows that landscape diagram with a notably lower number of gray dots designating the matching patent documents. This indicates a less thoroughly patented environment with potentially more new patenting opportunities. Again, reviewing the patent documents shown in the valleys of the topographical diagram can often lead to insights regarding unique patenting topics.
Exhibit 6: Landscape Query for “cas13”
PatSnap also provides an additional technique to analyze specific portions of the landscape diagram in more detail via its “Select Grid(s)” option available in the lower right corner of the diagram. Exhibit 2 showed the landscape with this select-grids capability activated. This shows the high-level groupings of the patent documents and the fainter background outlines of the grids on the diagram. The landscape diagram is essentially partitioned via horizontal and vertical grid squares. These squares can be selected so that the patent documents in the selected areas can be further analyzed by either exporting those specific patent documents or by computing a new landscape utilizing only the documents in the selected area.
For example, the landscape diagram shows a significant topographical valley in the lower left quadrant. This is potentially a white-space patenting opportunity area that needs further analysis. To do this, the grid squares covering this valley can be selected, as shown in Exhibit 7. The display indicates that nine grid squares have been selected, with 59 patent documents included in that selected area. Via the “View Patents” option in the lower right corner, these patent documents can be viewed in a list format and exported in a spreadsheet format for further examination. In addition, via the “New Landscape” option, a new landscape can be computed using only the documents from the selected grids. This new landscape is shown in Exhibit 8 and can be further explored via the same interactive querying process described here in step 4. Note that this new landscape diagram isn’t simply a zoomed-in image of the original landscape section but rather a newly computed landscape using the selected 59 patent documents as a new domain collection.
Exhibit 7: Landscape with Valley Grid Squares Selected
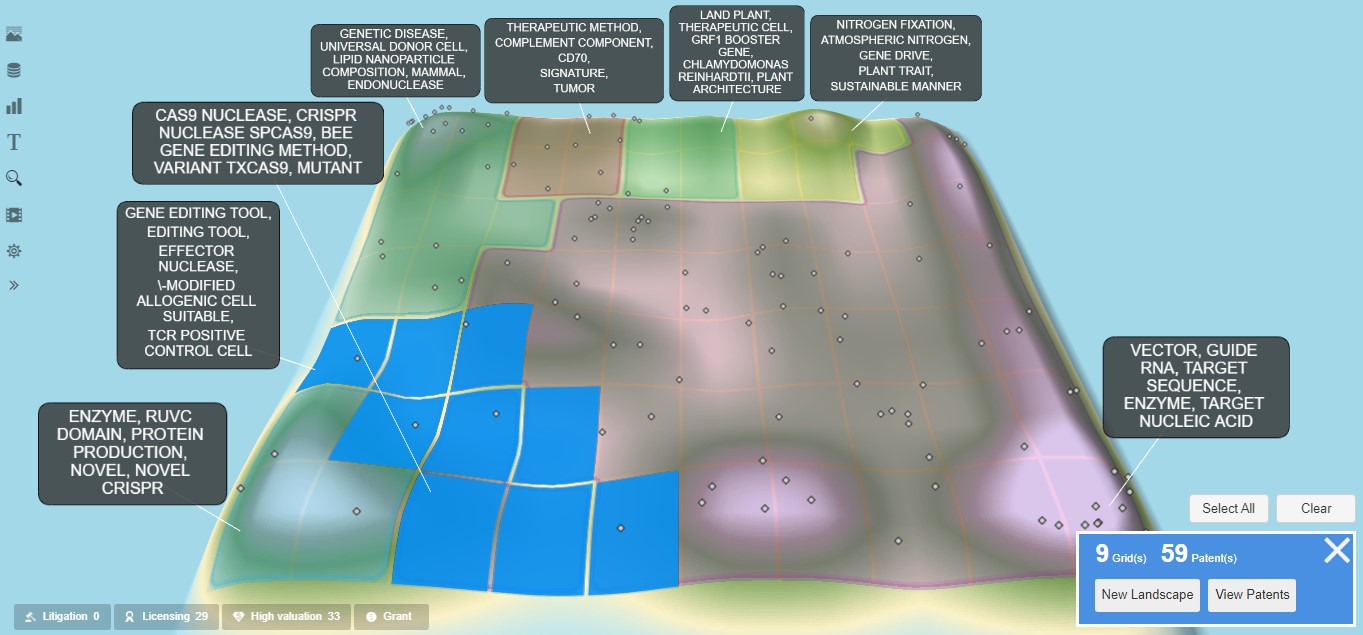
Exhibit 8: New Landscape from 9 Selected Grid Squares

As a final query example, “csm complex” is entered into the Simple search field. This key phrase is intended to represent a very recent development from Dr. Jennifer Doudna’s lab at the University of California, Berkeley, where multi-protein CRISPR-Cas effector complexes were shown to target RNA more effectively than the Cas13 nuclease. This was posted to the bioRxiv website on June 20, 2022, via a report entitled “Precise Transcript Targeting by CRISPR-Csm Complexes” and announced via the Doudna Lab Twitter feed (@doudna_lab) on June 21, 2022.
The landscape diagram for this query is shown in Exhibit 9 and indicates only six matching patent documents; three from Caribou Biosciences, one from the University of California Berkeley, and two from joint assignees North Carolina State University and BASF Plant Science Company GMBH. The patent application document specifically pertaining to the June 20, 2022, UC Berkeley announcement is not included in this landscape due to the publishing delay associated with new application filings. The low number of matching patent documents indicates the early stage of IP developments in this area as well as the potential for new patenting opportunities.
Exhibit 9: Landscape Query for “csm complex”

This situation, where the new UC Berkeley development isn’t yet included in the available patent documents, can be used to exemplify another PatSnap capability that’s useful for white-space research: the placement of free-form text descriptions on the landscape diagram. This capability is quite useful when a landscape has been created, and a text description of an innovation is semantically placed on the landscape to determine the description’s relative landscape position and its proximity or similarity to other patent documents in the domain collection. This technique of entering text descriptions can be used iteratively to refine ongoing R&D as well as assess competitive and FTO issues for new innovations.
Within the PatSnap tool, the text description entry capability can be found via the “Text Analysis” option on the left sidebar of the landscape diagram. This option allows for the entry of a title and a text description, after which the tool computes the semantic location of the entered text on the landscape diagram. For example, if the title and abstract of the UC Berkeley bioRxiv published report are entered, PatSnap computes a landscape location of that entered text as indicated by the red triangle in the lower right corner of the landscape diagram shown in Exhibit 10. This placement may require additional research as it is near a high patent document concentration area. But it is indeed not located near any of the other “csm complex” matching documents, indicating some level of uniqueness within the subdomain identified by that query.
Exhibit 10: Landscape with UC Berkeley Report Semantic Placement

Step 5: Iterate the White-space Research Process
The final step in this white-space research process is simply the iterative application of the preceding steps. This includes executing additional queries on the landscape diagram, selecting alternative grid partitions for detailed analysis, placing other experimental text descriptions on the landscape, or even generating new alternative domain collections to analyze. This is one of the most powerful advantages of applying data science and analytics to the white-space research process, as all of these can be executed quickly in an iterative fashion.
It's sometimes argued that the application of data science techniques to white-space research can produce slightly suboptimal results. This is usually associated with the techniques used to derive patent document similarities (semantic analysis, natural language processing, and machine learning), as well as the plotting of the document similarity clusters on a topographical landscape diagram and the use of this derived landscape to query for white-space patenting opportunities. While automated analysis techniques can result in some inaccuracies, today’s text similarity processes are dramatically better and, in particular, substantially faster than any classical white-space search techniques. So, the additional capability to quickly iterate the steps and techniques described in this report can add significant value that far outweighs any inaccuracies resulting from the application of data science to derive document similarities. The application of data science to processes like white-space research is and will continue to be the gold standard for the derivation and extraction of business intelligence from big data repositories such as patent documents.
About the Author: Jim Moeller provides customized consulting services leveraging analytics and data science tools for data integration and intelligence mining, aimed at projects focused on intellectual property research, market analysis, and business development. Executed project domains have covered medical devices, pharmaceuticals, biotechnology, digital and connected health, wearables, telemedicine, IoT (Internet-of-Things), and wireless communications. Jim is a U.S. Registered Patent Agent with experience spanning consulting, investment banking, and engineering. https://www.MoellerVentures.com