
IP Landscapes - Process & Descriptions
James H. Moeller - Moeller Ventures LLC - https://www.moellerventures.com/
Update: 2020-04-20
Overview:
A patent landscape study is a research process that filters and analyzes patent and patent application information to produce strategic business information that provides overview insights into competitors, technologies, and markets.
The patent landscape process used for Moeller Ventures IP reports utilize data science analytics and semantic analysis for the grouping of similar patents based on feature information, as well as common feature analysis to derive insights. These reports utilize Google's BigQuery cloud-based data warehouse service and the patent datasets provided in BigQuery. This project architecture enables the integration of the analysis into modern data science platforms. The results in Moeller Ventures IP reports have been produced via Python programs executed within Jupyter notebooks that access the BigQuery data warehouse via remote SQL queries.
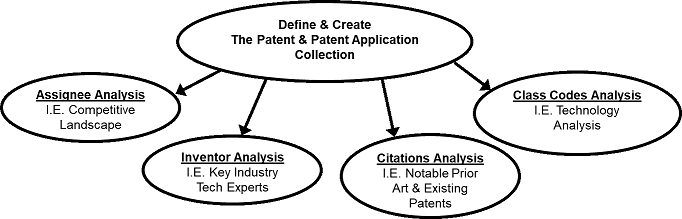
The diagram below shows the general analysis process. A collection of patent documents is created that represents the intellectual property domain to be analyzed. That domain collection of patent documents is then further grouped by specific feature information (e.g. assignees, inventors, citations, and class codes). Finally, the feature information is tabulated and analyzed to identify the trends and show insightful results focused on strategic business information such as the competitive landscape, key intellectual property experts, notable prior art, existing patents, and technology profiles.
Descriptions (Types of Landscapes):
There are many different types of IP landscapes and numerous ways to analyze patent information to derive a wide variety of results. For the process described above, the characterization of the landscape is largely determined by the definition and creation of the patent documents domain collection. Below are a few domain collection creation techniques that have been utilized in client projects and/or exemplified in reports available in the Intellectual Property Research public portfolio.
Domain Collections Creation Techniques:
- Topics, Keywords, and Key Phrases: This technique uses keywords and key phrases to create a patent documents domain collection representing topics or technology sectors via specific text matching to determine if a patent document should be included in the collection. This type of text query can match specific text in the patent document title, abstract, description, and claims, with keywords and phrases matched across all sections or sections independently. Below are examples of landscapes created using keywords and key phrases.
- Patent Documents Portfolio(s): This technique uses a specific set of patent documents as the domain collection and utilizes the patent documents’ application number or publication number to query the information about each document. This technique is typically applied in situations where there is a specific set of patent documents to be analyzed such as a corporate portfolio or a portion of a portfolio.
- Assignee Name(s) / Company Name(s): This technique creates a domain collection by matching assignee names. The assignee names could be a single corporation, a group of companies representing an industry sector, an educational or research institution, or even individuals that are listed as assignees. Below is an example of a landscape created from an assignee domain collection where 33 corporation names, representing the 33 leading companies competing in the telemedicine sector, were matched as assignees in creating the sector-focused domain collection.
- “Similar Patents” / Google Machine-Learned (ML) Similars: This technique utilizes the “google_patents_research” dataset available in Google’s BigQuery data warehouse cloud service. This dataset contains lists of similar patents which were derived by Google via machine learning models that identify the similarity of patent documents. Google’s model for predicting similar patents was derived from a machine learning process that was trained on over 15 million patents for which the full text and corresponding CPC classification codes (and other metadata such as citation similarities) were available. The google_patents_research dataset contains lists of up to 25 most-similar patents for much of the nearly 100 million patent documents available in BigQuery via the “patents-public-data” dataset. So, given an initial set of patent documents the Google similars lists can be utilized to find the most similar patent documents around the initial set. This can be used to create a domain collection consisting of the Google ML similars around a set of patent documents to be analyzed. For example, the first link below is to a landscape created from a domain collection consisting of the most similar patents of the 10 patents involved in the Masimo / Cercacor vs. Apple lawsuit. The remaining links are references to Google’s ML similars dataset.
- Patent Landscape Around 10 Patents Involved in the Masimo / Cercacor vs. Apple Lawsuit.
- Expanding your patent set with ML and BigQuery – 2019-08-30.
- European Patent Office – E-Learning Center - 2017: Making Patents Universally Accessible and Useful. A 2017 presentation by Ian Wetherbee, Manager, Google Patents.
- Google Patents Public Datasets: connecting public, paid, and private patent data – 2017-10-31.
- Combinations of the Above: Combinations of the techniques above can also be applied to derive additional insights. For example, a corporate portfolio landscape could be executed that focuses specifically on the patent documents of a specific company, and then the Google ML similars could be applied to all the documents in that corporate domain collection to derive the most similar patents to the corporate portfolio. A landscape analysis can then be performed on these similars to profile the patent landscape around the corporate portfolio. Likewise, a technology sector domain collection (derived via keywords / key phrases) or a competitor sector domain collection (derived via an assignee match to a group of company names) could be used as the basis in applying similars to those domain collections and effectively create landscapes around the technology sector or around the competitor sector.