
Update Note Sept 20, 2018: Google’s patents-public-data.patents.publications dataset has been updated as of Sept 18, 2018.
Google’s BigQuery data warehouse is one of the more interesting capabilities within their cloud offering and when it’s combined with their public datasets it can be a powerful platform for some very efficient patent research. While BigQuery was introduced back in 2010, the public patents datasets were not added until October 2017. So, it’s a relatively new patent data resource. Here is the link to the blog post introducing the public patents datasets; https://cloud.google.com/blog/big-data/2017/10/google-patents-public-datasets-connecting-public-paid-and-private-patent-data.
Essentially the combination of BigQuery and the public patent information enables a platform with ready-made datasets that can be queried with SQL (Structured Query Language - https://cloud.google.com/bigquery/docs/reference/standard-sql/). The public availability of these datasets can be a significant time and expense saver compared to crafting your own patent database from USPTO data or subscribing to commercial services. The BigQuery queries can be created and managed through the Google Cloud Portal, a command line tool, or with REST APIs and client libraries for Java, .NET or Python (https://cloud.google.com/bigquery/what-is-bigquery). In addition, the user can add their own private datasets to BigQuery (https://cloud.google.com/bigquery/docs/datasets) and/or access other commercially available datasets, that are available through BigQuery, to augment patent searches by combining that information into their query projects (Data Enrichments: https://console.cloud.google.com/marketplace/details/google_patents_public_datasets/ifi-claims-patent-data-enrichments). BigQuery charges are based on the amount of data processed in the query. The first 1 TB per user per month is free, then beyond that billed at $5.00 per terabyte. User’s datasets are billed at Google’s data storage rate at $0.02 per GB per month with the first 10 GB free each month, and then access to other commercial datasets are dependent on the rates set by the data provider. See Google BigQuery Pricing: https://cloud.google.com/bigquery/pricing#queries.
The first objective of this report is to experiment with BigQuery and Google’s public patent data via some queries that help characterize the datasets and aid in an understanding of writing queries and interpreting results. Then the second objective is to exemplify a simple keyword phrase query as a basis for more sophisticated patent searches.
Characterizing Google’s Public Patent Data
Most data science projects begin with an analysis of the problem or issue to be addressed and follow that with the preparatory data collecting, formatting and cleaning, all before any insightful analysis begins. But with Google’s BigQuery and the public patent datasets we can skip all that initial data preparation. However, that still doesn’t mean we can jump directly into insightful analysis. An understanding of the data that’s available is required.
There are actually quite a few datasets included in Google’s Patents Public Data. The following link will connect to the Google Cloud page for the general overview; https://console.cloud.google.com/marketplace/details/google_patents_public_datasets/google-patents-public-data. But to examine the detailed datasets you’ll need to sign-in to a Google Cloud account. As of this writing there are 19 different datasets spanning information such as patent classifications, standards essential patents, chemical compounds, patented drugs, patent litigation, USPTO information, and others. For this report I’ll be examining the “patents.publications” dataset, which is provided by IFI CLAIMS Patent Services, and is a “worldwide bibliographic and US full-text dataset of patent publications” (https://www.ificlaims.com/news/view/blog-posts/public-patent-data-now.htm). IFI CLAIMS also provides some other dataset (“IFI Data Enrichments”) that are available via a separate subscription (https://www.ificlaims.com/news/view/blog-posts/ifi-data-on-google.htm).
So what exactly is contained in the “patents-public-data.patents.publications” dataset? As the description says, it contains bibliographic information from a very broad database of worldwide patents and also full-text information on US patents. The next level of detail can be found by diving into the individual dataset tables within the Google Cloud query GUI, “patent.publications” in this case, and by examining the “Details” tab. Here you’ll find the size of the table, the number of rows, and the date when the table was last updated. The last-updated date can vary depending on the dataset and the type of information it contains. This can potentially be an issue for projects that require timely patent data, as Google hasn’t necessarily been super prompt in updating datasets. For example, the patents.publications dataset aims for a quarterly update frequency, however as of this writing, the last-updated date for the dataset is Feb 23, 2018. More information on these types of issue can be found on Google’s Patents Public Datasets forum at the following link; https://groups.google.com/forum/#!forum/patents-public-data.
The next level of dataset detail can be found on the “Schema” and “Preview” tabs of the individual dataset tables in the Google Cloud query GUI. Here you’ll find a brief description of every field in the dataset (i.e. the schema), and an example record shown in the preview tab. When characterizing the data, the schema is quite important. You’ll want to review this in fine detail when you’re writing queries so that you understand the data type and structure of each column. For example, date fields in the patents.publication dataset have an INTEGER type representation of YYYYMMDD (year-month-day), not the typical DATE type representation often used in SQL. In addition, related data is sometimes “nested” in a single field and needs to be un-nested to access the individual fields. Examples of these can be found in my queries below.
Characterizing the datasets further requires some basic data exploration via queries. These queries will be specific to the dataset being utilized. For the patents.publication dataset, its insightful to initially query for the date and geographic coverage to get a feel for the timeliness and global breadth of the information. Then to enable the keyword phrase searches, it’s useful to explore some text fields on which queries can be executed.
Query #1 below looks for the MIN and MAX patent publication dates, which shows the earliest publication date of July 4, 1782 and the most recent date of Feb 7, 2018, as shown in Figure 1. A similar query can be written for MIN and MAX patent grant dates, also shown in Figure 1. Google Data Studio is used as the presentation medium, so the figures below are screen-shots of the report pages. The live embedded report can be view on the Moeller Ventures website at the following link. https://www.moellerventures.com/index.php/CharGPatPubDataPatentsPublications.
Query #1
#standardSQL
-- PublishedPatentApps_PerYear_PerCountry
SELECT
MIN(publication_date) AS Earliest_Patent_Publication_Date,
MAX(publication_date) AS MostRecent_Patent_Publication_Date
FROM
`patents-public-data.patents.publications` AS patentsdb
WHERE
publication_date > 0;
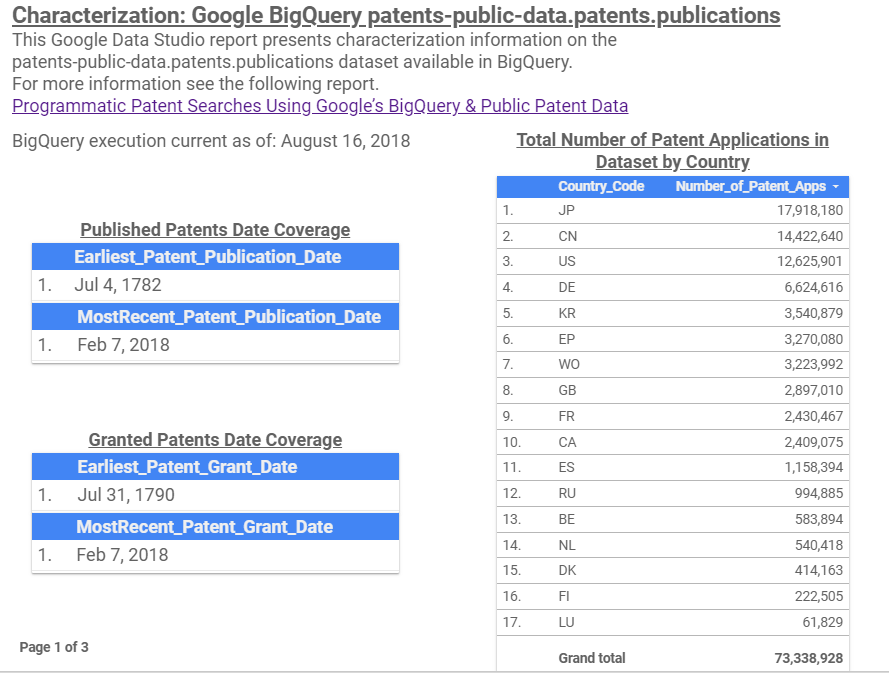
Figure 1
Query #2 below helps gain an understanding of the geographic coverage of the dataset by showing the total number of patent applications by country. A similar query can be used to list the number of granted patents. These tables are shown in Figure 1 and Figure 2 (Page 1 and Page 2 of the report). Note that the granted patents table includes both Utility and Design patents. The Country Code references in the tables can be found at the following link: https://www.uspto.gov/patents-application-process/applying-online/country-codes-wipo-st3-table.
Query #2
#standardSQL
-- Applications_Per_Country
SELECT country_code AS Country_Code, COUNT(*) AS Number_of_Patent_Apps
FROM (
SELECT ANY_VALUE(country_code) AS Country_Code
FROM `patents-public-data.patents.publications` AS patentsdb
GROUP BY application_number
)
GROUP BY Country_Code
ORDER BY Number_of_Patent_Apps DESC;
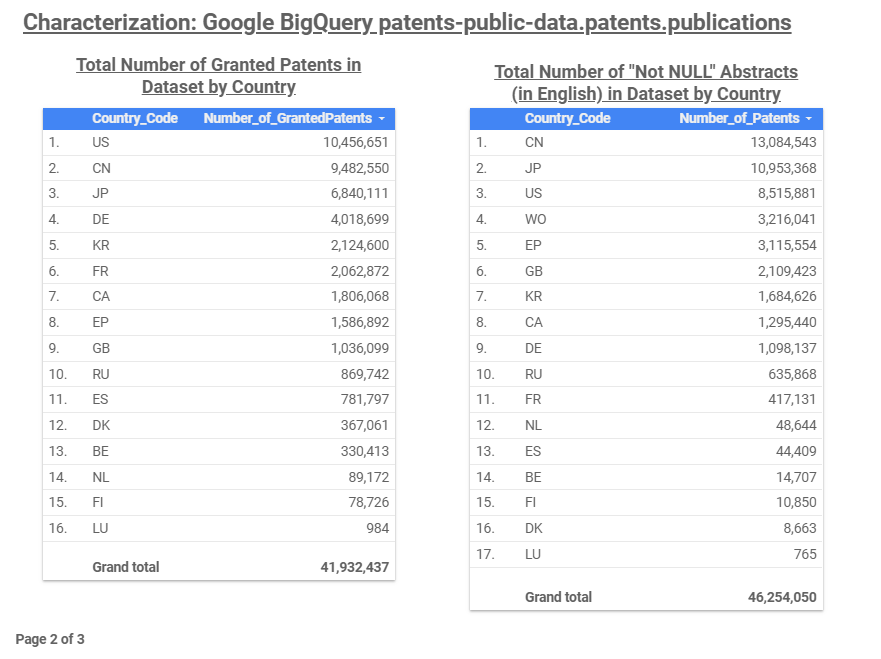
Figure 2
Finally, Query #3 is used to find text fields on which keyword phrase queries can be executed. This query lists the total number of patents, by country, that had an English abstract that was not empty (i.e. Not NULL). That table is also shown in Figure 2. This table shows that we have English patent abstracts for ~46 million of the ~73 million patent applications present in the dataset. As a further verification of the data, a similar Not NULL query can be executed on the patent claims field and the patent description field. Those results are shown in Figure 3 and, as expected, only show a result for the U.S., since the dataset only includes bibliographic patent information (no claims or descriptions) for non-U.S. patents.
Query #3
#standardSQL
-- NotNULLAbstracts_PerCountry
SELECT COUNT(*) AS Number_of_Patents, country_code AS Country_Code
FROM (
SELECT ANY_VALUE(country_code) AS Country_Code
FROM `patents-public-data.patents.publications` AS patentsdb,
UNNEST(abstract_localized) AS abstract_info
WHERE
abstract_info.text IS NOT NULL
AND
abstract_info.language = 'en'
AND
CHARACTER_LENGTH(abstract_info.text) > 10
GROUP BY application_number
)
GROUP BY Country_Code
ORDER BY Number_of_Patents DESC;
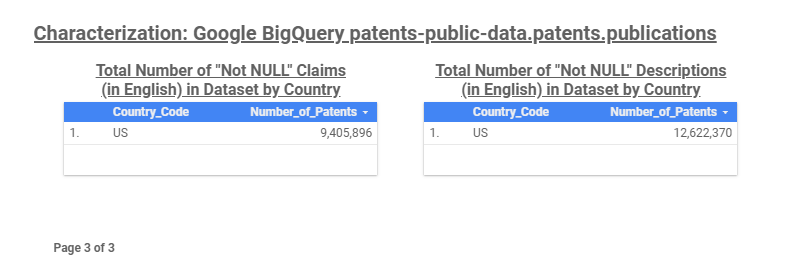
Figure 3
Example Keyword Phrase Search Query
Now armed with a better understanding of the patents-public-data.patents.publications dataset, the next objective is to work with some keyword phrase queries to derive some intelligence from the dataset. From a keyword phrase perspective, the abstract is the only text field that spans the international patent applications in the dataset, so that will be the focus in order to provide an international perspective to the results. As noted above, there are ~46 million English abstracts spanning the patent applications from the various countries as listed in the right-hand table of Figure 2. The query chosen to exemplify a keyword phrase search is one that simply produces time-series data representing the number of patent applications that use a specified keyword phrase.
Query #4, listed below, implements that keyword phrase, time-series data search and uses the keyword phrase of “internet of things”. The keyword phrase of “internet of things” was chosen because it’s a relative new patent literature term within the last decade, but the query can be modified to search for any keyword phrase. In addition, the WHERE clause of Query #4 also limits the search to U.S. patents. The specific results data for this query is shown in Figure 5 below. The query results spanning all English patent application abstracts, with the WHERE clause removed, is shown in Figure 4. Again, Google Data Studio is used to present the bar charts. The figures below are the screen-shots of the charts, and the live embedded report can be viewed on the Moeller Ventures website at the following link; https://www.moellerventures.com/index.php/GPatPubDataIoTKeyPhrase.
So, Figure 4 shows the barchart of the phrase “internet of things” from a global patent application perspective and indicates that the earliest patent literature usage (at least in the abstract) was in December of 2007, but the term really started to get popular midyear 2010 and seems to have peaked midyear 2016. Figure 5 shows the results for the ~8.5 million U.S. patent applications and indicates a similar trend.
Query #4
#standardSQL
-- This counts the number of U.S. patents matching the phrase on a monthly basis.
WITH
Patent_Matches AS
(
SELECT
PARSE_DATE('%Y%m%d', SAFE_CAST(ANY_VALUE(patentsdb.filing_date) AS STRING)) AS Patent_Filing_Date,
patentsdb.application_number AS Patent_Application_Number,
ANY_VALUE(abstract_info.text) AS Patent_Title,
ANY_VALUE(abstract_info.language) AS Patent_Title_Language
FROM
`patents-public-data.patents.publications` AS patentsdb,
UNNEST(abstract_localized) AS abstract_info
WHERE
LOWER(abstract_info.text) LIKE '%internet of things%'
AND patentsdb.country_code = 'US'
GROUP BY
Patent_Application_Number
),
Date_Series_Table AS
(
SELECT day, 0 AS Number_of_Patents
FROM UNNEST (GENERATE_DATE_ARRAY(
(SELECT MIN(Patent_Filing_Date) FROM Patent_Matches),
(SELECT MAX(Patent_Filing_Date) FROM Patent_Matches)
)) AS day
)
SELECT SAFE_CAST(FORMAT_DATE('%Y-%m',Date_Series_Table.day) AS STRING) AS Patent_Date_YearMonth, COUNT(Patent_Matches.Patent_Application_Number) AS Number_of_Patent_Applications
FROM Patent_Matches
RIGHT JOIN Date_Series_Table
ON Patent_Matches.Patent_Filing_Date = Date_Series_Table.day
GROUP BY Patent_Date_YearMonth
ORDER BY Patent_Date_YearMonth;
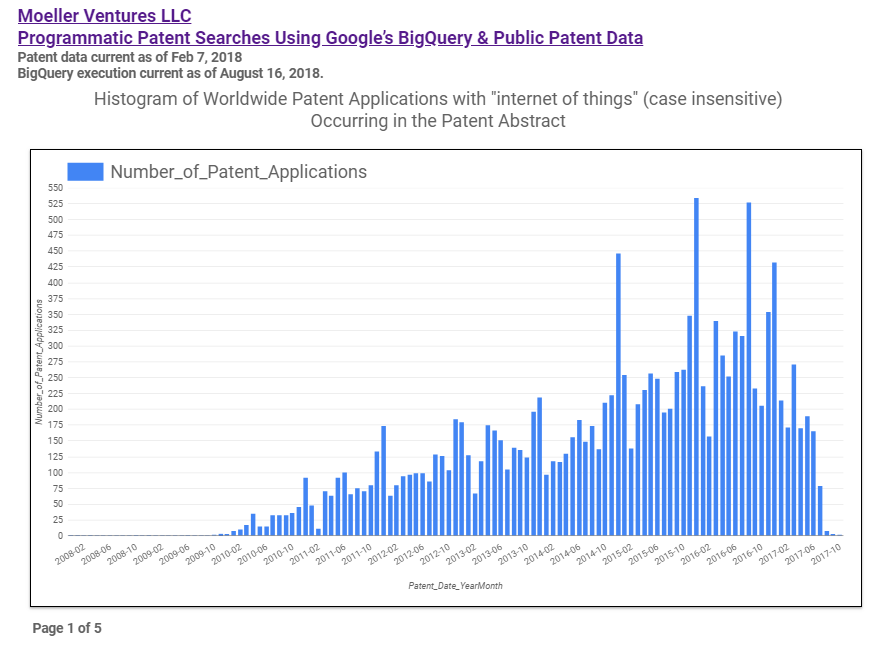
Figure 4
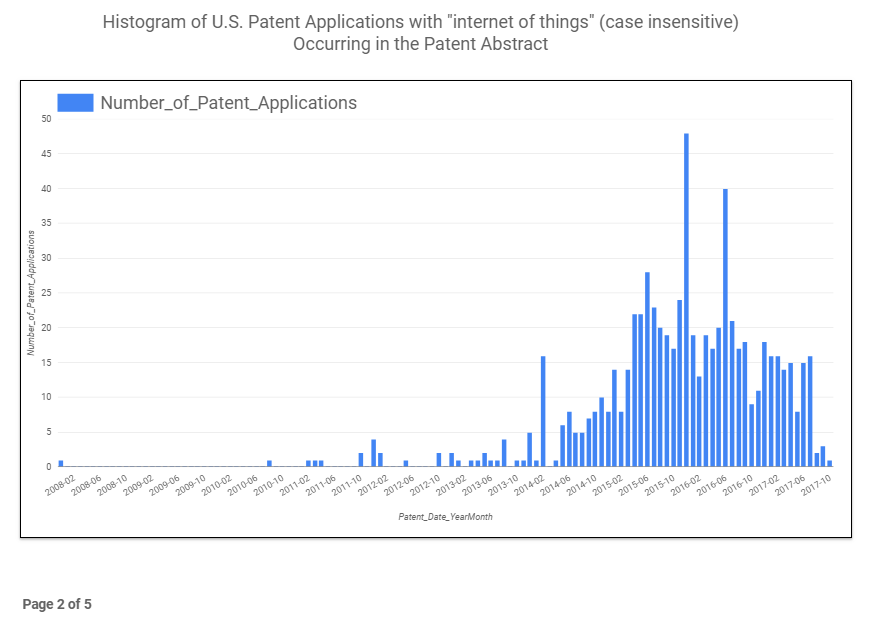
Figure 5
Figure 6 shows the term’s usage in patent applications filed in China (queried across ~13 million patent applications) and shows the very high usage of “internet of things” in Chinese intellectual property over the last eight years. In fact, the China numbers are so dramatic that they really dwarf the term’s usage in patent literature from any other country. This trend also correlates with the dramatic rise in patent application filings in China over the last five to ten years.
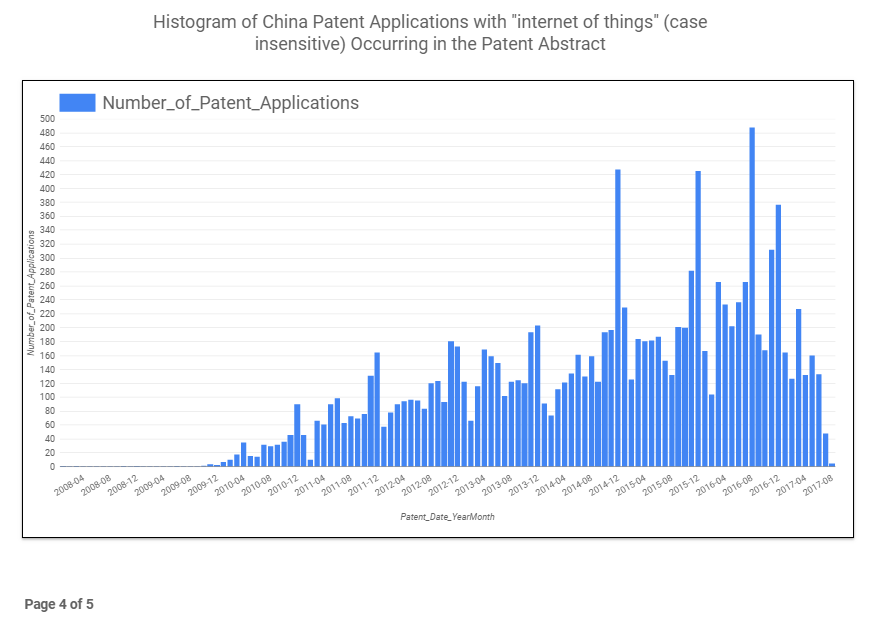
Figure 6
Finally, Figure 7 shows the same query executed for patents in Japan (queried across ~10.9 million patent applications), and interestingly shows very low usage of the “internet of things” phrase. This seems odd as one might expect more patent applications in Japan that are applicable to the IoT market and thus potentially using that phrase. More research is needed to determine if there is a translation issue involved with this potential abnormality. This does, however, exemplify the difficulty in using keyword phrases in patent searches where language translations can result in different terminology for commonly understood terms.
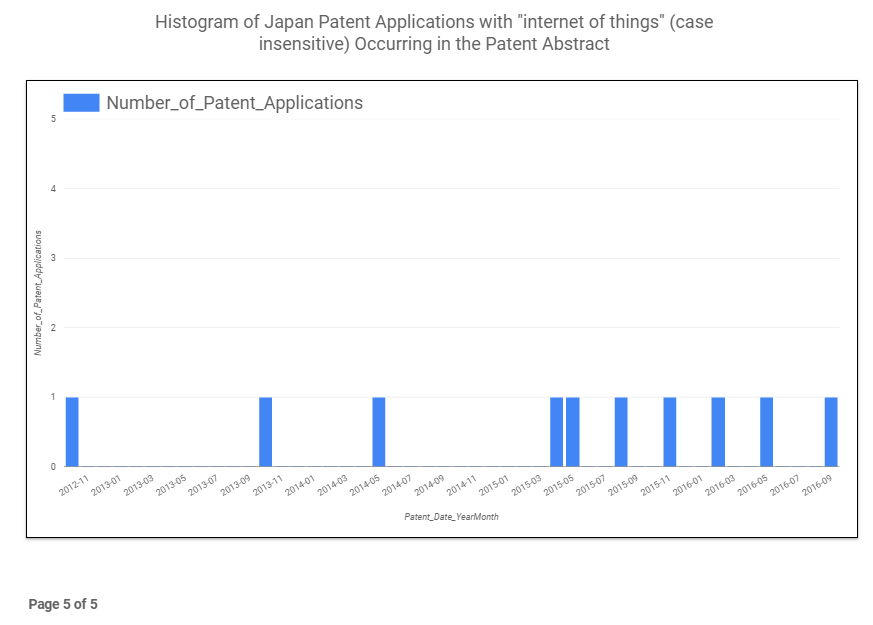
Figure 7
The Take-Aways
- Overall, the combination of Google’s BigQuery data warehouse and public patent data can be a very powerful tool to quickly implement efficient patent searches via SQL.
- Google offers a wide variety of public patent datasets that can be utilized for different types of search projects. Each dataset will likely require some level of characterization work to understand the dataset prior to any insightful analysis.
- The combination of BigQuery and the patents-public-data.patents.publications dataset, creates a platform that excels at the capability to quickly and inexpensively query information from a large number of patents and applications. The BigQuery patent.publications dataset contains bibliographic information from over 73 million patents and applications worldwide and full-text information from over 12 million U.S. patents and applications.
- The timeliness of Google’s public patent datasets can sometimes be an issue, as the datasets are not currently updated very frequently. That said, as a newer offering, it’s reasonable to expect the timeliness of the data to improve.
- Keyword phrase queries can be utilized very effectively to find patents and patent applications of interest. The keyword phrase, time-series data query exemplified in this report can be modified to search for different keyword phrases and different countries and can be used as a basis for more complex patent searches.
- The specific keyword phrase analysis in this report focused on the phrase “internet of things” and shows the initial use of the phrase in patent literature in December of 2007, the increase in usage midyear 2010, and the peak usage midyear 2016. In addition, the analysis shows the heavy usage of the phrase in Chinese patent applications and conversely the lack of usage in Japanese patent applications. More research is needed to determine if these potential abnormalities are due to language translation issues.
Further Reading:
- Google Patents Public Datasets: connecting public, paid, and private patent data (October 31, 2017): https://cloud.google.com/blog/big-data/2017/10/google-patents-public-datasets-connecting-public-paid-and-private-patent-data
- BigQuery Standard SQL Reference: https://cloud.google.com/bigquery/docs/reference/standard-sql/
- BigQuery Creating and Using Datasets: https://cloud.google.com/bigquery/docs/datasets
- IFI Claims Data Enrichments: https://console.cloud.google.com/marketplace/details/google_patents_public_datasets/ifi-claims-patent-data-enrichments
- Google BigQuery Pricing: https://cloud.google.com/bigquery/pricing#queries
- What is BigQuery?: https://cloud.google.com/bigquery/what-is-bigquery
- Google Patents Public Data Overview: https://console.cloud.google.com/marketplace/details/google_patents_public_datasets/google-patents-public-data
- IFI CLAIMS Patent Services - Public Patent Data Now Available on Google BigQuery: https://www.ificlaims.com/news/view/blog-posts/public-patent-data-now.htm
- IFI CLAIMS Data on Google BigQuery Untangles the PTAB: https://www.ificlaims.com/news/view/blog-posts/ifi-data-on-google.htm
- Google’s Patents Public Datasets Forum: https://groups.google.com/forum/#!forum/patents-public-data
- China Drives International Patent Applications to Record Heights; Demand Rising for Trademark and Industrial Design Protection: http://www.wipo.int/pressroom/en/articles/2018/article_0002.html
- Increases in Innovation, Patent Boom Leads to Development in China: http://www.ipwatchdog.com/2018/04/18/increases-innovation-patent-boom-development-china/id=95994/